Abstract
This report details a coding project aimed at leveraging Natural Language Processing (NLP) techniques to extract and analyze information from TC meeting notes, a crucial aspect of the ECMAScript standardization process. The background provides context on ECMAScript, TC39, and the significance of meeting notes in shaping web development. The implementation outlines the meticulous process of text extraction and the application of various NLP techniques, from sentiment analysis to semantic role labeling. The resulting data structure in JSON format offers a clear representation of the extracted information, while a sentiment graph visually depicts emotional dynamics within proposals. The project aligns with a broader goal of enhancing transparency and collaboration within the ECMAScript standardization process, empowering developers with nuanced insights into language changes and committee discussions.
Introduction
The ECMAScript standard stands as a foundational element, providing the guidelines upon which the scripting language JavaScript is built. The continuous improvement of ECMAScript is steered by the TC39 committee, a vital body within Ecma International. This committee, comprised of representatives from diverse organizations, plays a pivotal role in shaping the standard, ensuring its consistency and adaptability across various implementations.
The focus of this coding project is to explore Natural Language Processing (NLP) techniques for extracting and analyzing information embedded within the meeting notes of the TC39 committee. The meeting notes serve as a comprehensive record of discussions, decisions, and proposals, reflecting the dynamic nature of the ECMAScript standard evolution.
This report details the background of ECMAScript and the role of the TC committee, emphasizing the significance of their meeting notes in tracking the development of the language. Subsequently, it delves into some NLP techniques, ranging from sentiment analysis to semantic role labeling, highlighting their relevance in understanding the nuances of textual content.
The implementation section provides a step-by-step walkthrough of the script’s design, explaining how text extraction, timestamp identification, proposal section recognition, and utterance processing are performed. The utilization of frameworks such as TextBlob, Universal Sentence Encoder, Yake, and others is detailed, showcasing a first draft approach to information extraction and analysis.
Visual representation in the form of sentiment graphs enhances the interpretability of the data, allowing for a deeper understanding of sentiment dynamics within each proposal. Additionally, the JSON format output provides a structured and readable overview of the processed data, facilitating further analysis or sharing of results.
Related work is discussed, introducing NLP libraries like Stanza and Spacy, along with the Hugging Face Sentence Transformer model. These resources serve as benchmarks and alternatives, highlighting the diversity of tools available in the NLP landscape.
This project aims to create a tool that applies NLP techniques on TC39’s meeting notes. It has the goal of extracting valuable information from the corpus that can provide deeper understanding about how a proposal is discussed, participants’ attitudes towards it and how this changes over time.
Background
ECMAScript
ECMA-262 is a scripting language specification that serves as the standard upon which JavaScript is based. It is developed and maintained by Ecma International, a standards organization. ECMAS-262 provides the rules and guidelines that a scripting language must follow to be considered ECMAScript- compliant.
JavaScript is the most well-known implementation of ECMAScript, but other languages like JScript and ActionScript also adhere to the ECMAScript standard. The goal of ECMA-262 is to standardize the scripting language to ensure interoperability and consistency across different web browsers and environments.
The ECMAScript specification evolves over time, with new features and improvements being added to meet the demands of developers and the evolving landscape of web development. Each version of ECMAScript introduces new features, enhancements, and bug fixes. Developers often refer to the different versions of ECMAScript by their edition number, such as ECMAScript 6 (ES6) or ECMAScript 2015, which brought significant enhancements to the language. Subsequent editions, like ECMAScript 2016, ECMAScript 2017, and so on, have continued to build upon the standard. With the most recent one at the time of writing being the 14th Edition, ECMAScript 2023.
TC39 committee
The TC39 (Technical Committee 39) is a committee within Ecma International responsible for the standardization of the ECMAScript programming language. The primary goal of TC39 is to develop, maintain, and evolve the ECMAScript standard.
TC39 is composed of representatives from various organizations, including browser vendors, language designers, interested parties from the software development community, and academia. The committee collaborates to propose and discuss new features, improvements, and changes to ECMAScript.
The process of introducing a new feature or modifying an existing one typically involves several stages within TC39:
Stage 0: An initial idea or proposal is presented as a strawman. This is an informal stage to get feedback and initial thoughts from the committee.
Stage 1: The proposal is formalized, and its high-level design and motivation are presented to the committee. If accepted, it moves to the next stage.
Stage 2: The proposal is further refined, and a preliminary specification is created. This stage involves more detailed discussions and collaboration on the proposed feature.
Stage 3: The proposal is considered feature-complete, and a complete specification is provided. At this stage, it is ready for initial testing and feedback from implementers.
Stage 4: The proposal has received feedback, has been tested, and is ready to be included in the ECMAScript standard. Once the committee reaches consensus, the feature is added to the standard.
The TC39 committee plays a crucial role in the ongoing development and improvement of ECMAScript, ensuring that the language evolves to meet the needs of developers and the changing landscape of web development. The committee’s work has a direct impact on the features and capabilities available to developers when writing JavaScript or other languages based on ECMAScript.
Meeting Notes
The TC39 meeting notes are documents that summarize the discussions, decisions, and outcomes of the committee’s meetings. These notes provide a detailed record of what was discussed during a particular meeting, including proposed language features, changes to the ECMAScript standard, and any other relevant topics.
Here are some key points about these meeting notes:
Agenda and Topics: Meeting notes typically include an agenda that outlines the topics to be discussed during the meeting. This could include specific proposals for new language features, updates on existing proposals, discussions about language design principles, and more.
Attendees: The notes often list the participants who attended the meeting, including representatives from various organizations, language designers, and interested parties. This provides transparency about who is contributing to the discussions.
Discussion and Decisions: For each agenda item, the notes summarize the discussions that took place. This includes the viewpoints expressed by different participants, potential concerns, and any decisions or outcomes reached by the committee. It provides insight into the reasoning behind the decisions made during the meeting.
Proposal Updates: If there are updates on specific language proposals (features being considered for inclusion in ECMAScript), the meeting notes will highlight these updates. This could include advancements to a higher stage in the proposal process or changes based on feedback received.
Actions and Next Steps: The notes often include action items and next steps that arise from the discussions. These could involve further research, addressing concerns, or preparing materials for the next meeting.
Links to Materials: Meeting notes may include links to additional materials, such as presentation slides, documents, or external references that were discussed during the meeting.
By reviewing these meeting notes, developers, implementers, and other interested parties can stay informed about the ongoing work of the TC committee. It allows the broader community to understand the rationale behind language changes, track the progress of specific proposals, and provide feedback on the evolving ECMAScript standard.
Markdown Files In the GitHub repository, at the root level of the GitHub repository, there may be various files and folders related to the TC39 project. Among them, there is a designated folder where meeting notes are stored, called “meetings”.
This folder contains folders representing each month of each year where there has been a meeting, meaning one folder for every two months since May of 2012. In each of these folders are the meeting notes, as well as other relevant files for the meeting, liketoc.mdandsummary.md.
However, the only relevant files for this project, is the meeting notes themselves.
Formatting of the meeting notes The meeting notes are formatted in such a way that each utterance can be tied to a specific person. In this way, what each person has to contribute to the current proposal is easily distinguishable from the other people involved in the meeting. It can be broken down in the following way.
Speaker’s Acronym: The three-letter acronym at the beginning of each line represents the identifier of the person speaking. These acronyms are usually unique to each participant and are used consistently throughout the meeting notes.
Colon (:) Separator: The colon serves as a separator between the speaker’s acronym and the content of their utterance. It visually distinguishes the speaker from their comment.
Utterance Content: Following the colon, the actual content of what the person is saying is presented. This is the substance of the participant’s contribution to the discussion, and it could include statements, questions, proposals, concerns, or any other relevant remarks.
Here’s an example fromfeb-01.mdin the2023-01-folder:
ABC: Just a note to SYG to follow up with offline and to everyone interested in implementing this and trying implementation...
DEF: Ephemeron collection.
ABC: Thank you. I was trying to remember the word. By doing the transpose thing, the case that needs to be cheap becomes cheap.
DEF: So there are a couple different implementation strategies. Trade off, the big O notation of the run, the get, or the wrap. (...)
In this example, ABC and DEF are three-letter acronyms representing different participants. After the colon, each line presents the content of the participant’s utterance or comment.
An Overview of NLP techniques
Sentiment Analysis is a natural language processing technique designed to discern and quantify the emotional tone expressed in a piece of text, typically categorized as positive, negative, or neutral sentiment. This process involves the use of machine learning algorithms to analyze words and phrases within a context, considering linguistic nuances and variations. Sentiment analysis is particularly valuable in the business realm for gauging customer satisfaction through reviews and social media comments. Additionally, it aids in monitoring public sentiment towards products, services, or brands, helping organizations make informed decisions based on the prevailing attitudes within the target audience. (Devopedia. 2022.)
Named Entity Recognition (NER) is a crucial component of information extraction in natural language processing. It involves identifying and classifying entities such as names of people, organizations, locations, dates, and other specific terms within a given text. NER systems employ machine learning algorithms that are trained on annotated datasets to accurately locate and categorize these entities. Applications of NER range from extracting structured information from unstructured text, improving search engine capabilities, to facilitating question-answering systems by identifying key entities within a document. (Devopedia. 2020.)
Semantic Role Labeling (SRL) is a semantic parsing task that focuses on understanding the relationships between different elements in a sentence by assigning specific roles to words or phrases, such as identifying the agent, patient, or beneficiary in a given action. This technique goes beyond traditional syntactic parsing to capture the deeper meaning and roles of each component within a sentence. SRL is instrumental in tasks requiring a nuanced understanding of natural language, including machine translation, question answering, and sentiment analysis, where discerning the roles of entities is crucial for accurate interpretation. (Devopedia. 2020.)
Part of Speech Tagging POS tagging, assigning part-of-speech tags to words, tackles ambiguity in natural language processing by resolving multiple meanings based on context. Originally linguistic, POS taggers transitioned to a statistical approach with models achieving over 97% accuracy. This pre-processing step is fundamental in NLP, supporting applications such as information retrieval, named entity recognition, and text-to-speech systems.(Devopedia. 2019.)
Text Summarization is a text processing technique that aims to distill the essential information from a document while preserving its core meaning. There are two main types of summarization: extractive , which selects and combines existing sentences, and abstractive , which generates new sentences to convey the summarized content. Summarization finds applications in news articles, research papers, and document management, providing a concise overview of lengthy texts and aiding in information retrieval and decision-making processes. (Devopedia. 2020)
Semantic Similarity quantifies the likeness between two pieces of text based on their meaning rather than relying solely on lexical or syntactic similarity. These measures take into account the context, semantics, and relationships between words, enabling a more nuanced understanding of similarity. Semantic similarity is applied in various NLP tasks, including duplicate detection, document clustering, and recommendation systems. By capturing the underlying meaning of text, semantic similarity enhances the accuracy and relevance of systems that require matching or grouping textual information. (Harispe et al., 2015)
Keyword Extration involves identifying and extracting the most relevant and significant words or phrases from a given text. This process helps to distill the key themes, topics, or concepts within a document, enabling a more concise representation of its content. NLP algorithms use various techniques, such as statistical analysis, natural language processing, and machine learning, to determine the importance of words based on their frequency, context, and relationships within the text. Ultimately, keyword extraction aids in summarizing and understanding the essential information contained in a body of text. (Beliga et al., 2015)
Implementation
In this project, i applied sentiment analysis, semantic similarity and keyword extraction on the meeting notes corpus. To extract relevant data and produce plots from the meeting notes, this seemed sufficient.
For this entire project, i’ve chosen to use python for the implementation of the techniques. This is mainly due to the vast amount of libraries available, but also because of the increased readability by most developers. In addition, it is also the language i’m the most confident in.
You can find the code for the implementation in my Github repository, which is listed in the references section. (Engelsen, 2023).
Text extraction
File Selection: The script uses the globmodule, which is a python module that can be applied to identify path names that fits a specified pattern, to identify markdown files within the specified directory, excluding certain files like “toc.md” or “summary.md.” This ensures that only relevant files are considered for processing, narrowing down the scope of analysis.
Reading Markdown Files: For each markdown file, the script opens and reads its content by using python’s builtinopenfunction and read method. The custom process_markdown_filefunction encapsulates this operation, facilitating the extraction of text from individual markdown files.
Timestamp Extraction: The code extracts timestamps from markdown file names by employing regular expressions to recognize patterns like month-day.md. It maps these patterns to corresponding month numbers and the current year, generating accurate timestamps for each proposal section.
Proposal Section Extraction: Within each markdown file, the script identifies proposal sections by applying a regular expression (proposal_section_pattern). The re.findall function is used to extract titles of these proposal sections, forming a list of titles for subsequent processing.
Utterance and Text Extraction: For each proposal section, the script iterates through its titles, extracting the corresponding text. It filters out irrelevant sections based on predefined criteria using theisDumbTitle function. Relevant text is then extracted by slicing the content based on the position of the title in the markdown text.
Text Cleaning: Extracted proposal text undergoes cleaning through regular expressions, removing undesirable information such as presenter details and slide references. Patterns like presenter names and slide references are identified and eliminated using the re.sub function, ensuring the text is focused on the core content.
Utterance and Sentence Processing: The script processes the proposal text by splitting it into utterances using a regular expression (utterance_pattern) to identify speaker contributions. Each utterance is further divided into sentences using there.splitfunction. Sentences are processed individually, and keyword extraction is performed using the Yake library.
Proposal Dictionary Object
The proposal dictionary encapsulates essential information about a specific proposal extracted from the meeting notes. Here is an explanation of properties of the object
title: This field stores the title of the proposal, providing a concise identifier for the proposal’s subject matter.
timestamp: Represents the timestamp associated with the proposal, typically extracted from the markdown file name.
utterances: This is a list containing individualutterancedictionary objects. Each utterance corresponds to a section of the proposal where a distinct speaker contributes.
full text: The entire content of the proposal is stored here, facilitating comprehensive analysis and comparisons.
Utterance Dictionary Object
Theutteranceobject represents a speaker’s contribution to the discussion which contains the utterance. Here is an explanation of properties of the object:
utterance_number: The chronological number of the utterance within the proposal.
timestamp: Carries the timestamp associated with the proposal. This will correspond to the date of the meeting, which is a date translated from the name of the markdown file.
sentences: This list contains the list of individualsentencedictionary objects, each representing a sentence within the utterance.
polarity: Represents the overall sentiment polarity of the entire utterance.
subjectivity: Reflects the subjectivity of the utterance as a whole.
keywords: Stores keywords extracted from the utterance using the Yake library, providing insights into the main topics.
Sentence Dictionary Object
Thesentenceobject represents an individual sentence within an utterance. Here is an explanation of properties of the object
sentence_number: A unique identifier for each sentence within an utterance.
text: a string containing the contents of the individual sentence.
polarity: The sentiment polarity of the sentence.
subjectivity: The subjectivity of the sentence.
Frameworks Used
TextBlob TextBlob is a library that simplifies common natural language processing tasks. In this script, it is employed for basic sentiment analysis, allowing the determination of the sentiment polarity and subjectivity of both sentences and entire utterances. (Loria, 2020)
Universal Sentence Encoder TensorFlow’s Universal Sentence Encoder (USE) is a pre-trained model that converts text into high-dimensional vectors. This script uses USE to generate embeddings for sentences, enabling the calculation of semantic similarity between different texts. (Cer et al., 2018)
Yake Yake is a keyword extraction library that identifies significant keywords within a given piece of text. In this script, Yake is utilized to extract keywords from each utterance, aiding in the understanding of the main topics discussed. (Campos et al., 2020)
Matplotlib Matplotlib is a plotting library in Python. In this script, it is used to create sentiment analysis plots. These plots visually represent how sentiment changes over the course of utterances in a proposal. (Hunter, 2007)
Regular Expression Regular expressions are applied for pattern matching and extraction. In this context, they help identify specific sections of markdown files and clean proposal texts by removing irrelevant information such as presenter details and slides. (Python Software Foundation, 2023)
TensorFlow TensorFlow is an open-source machine learning framework, and in this script, it is used to load and leverage a pre-trained model for encoding sentences into meaningful vectors. In this code, it is utilized to load and utilize the Universal Sentence Encoder model. (Abadi et al., 2015)
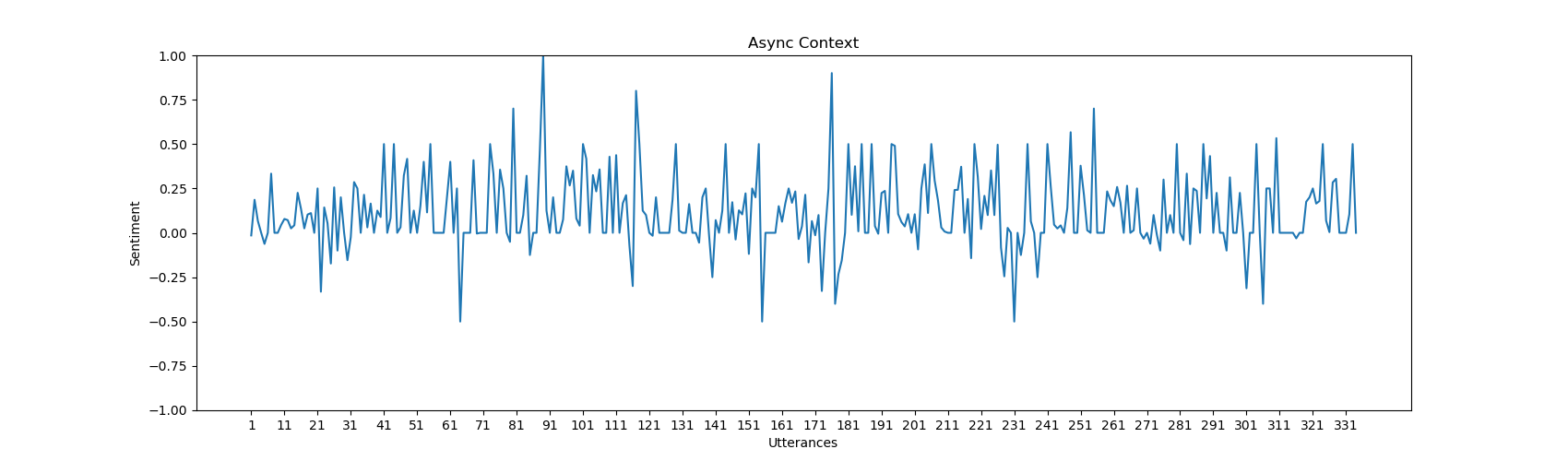
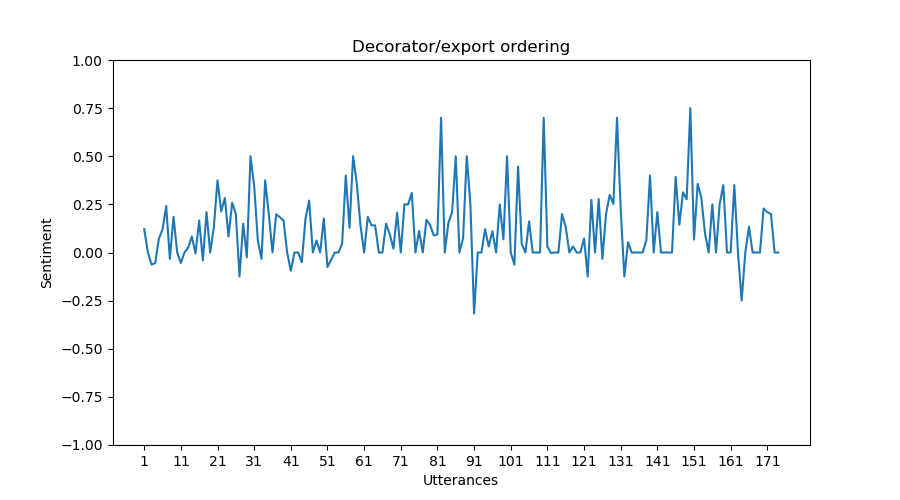
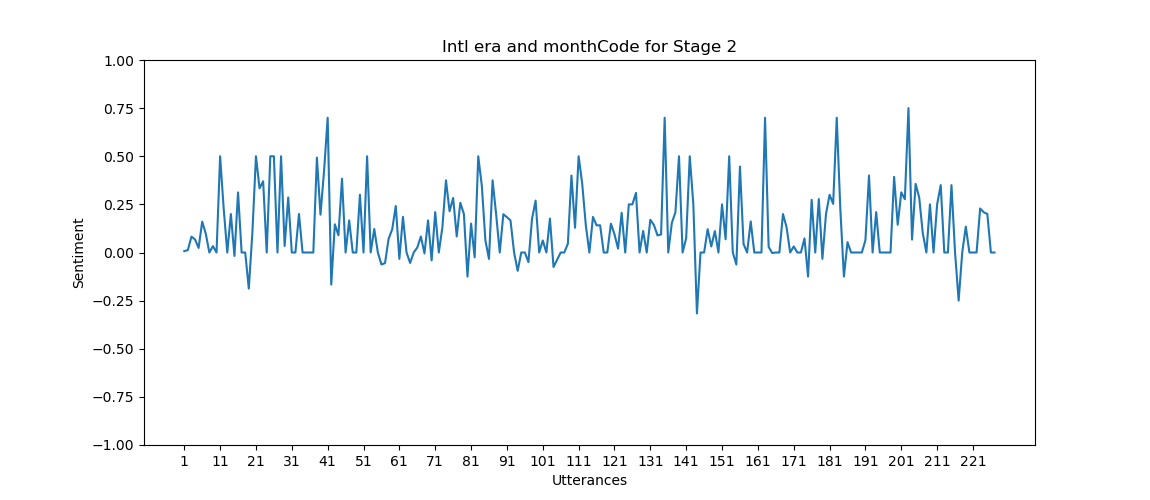
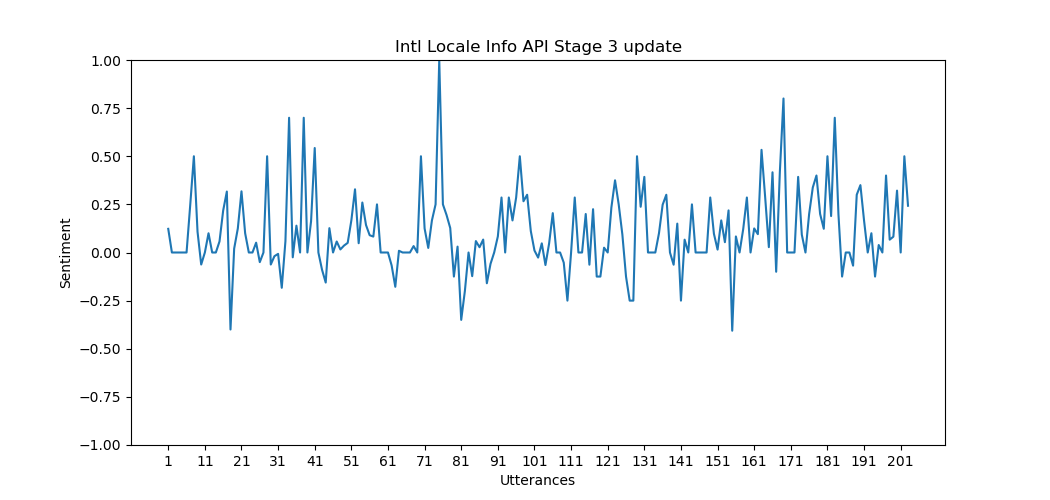
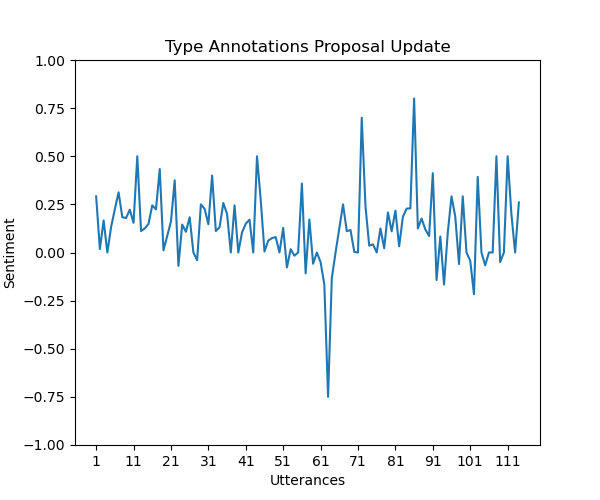
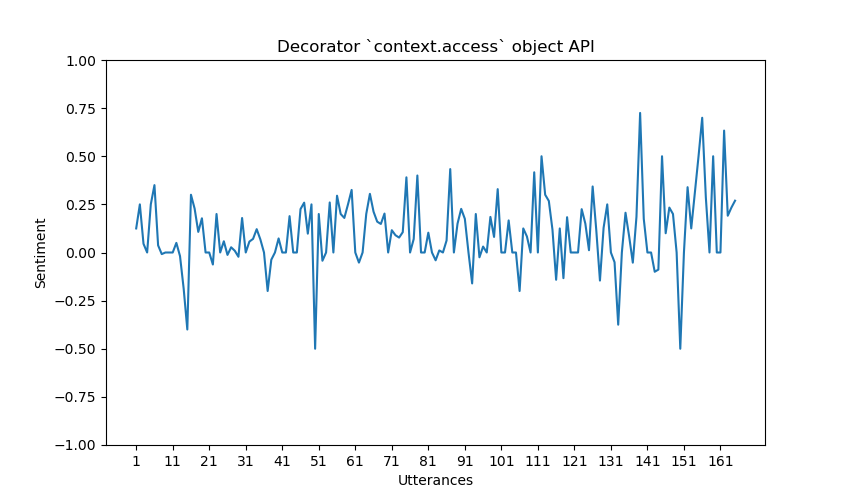
Sentiment Graph The sentiment graph is generated using Matplotlib and serves to visually depict the sentiment dynamics within a proposal. Here is an explanation of the graph-properties.
X-axis: Represents individual utterances within the proposal.
Y-axis: Depicts the sentiment polarity, showcasing shifts in sentiment from positive to negative between -1.0 and 1.0. -1.0 means completely negative, 0 means completely neutral and 1.0 means completely positive.
Highlights: Points on the graph highlight utterances with particularly high positive or negative sentiment, providing a quick overview of sentiment peaks and troughs. The utterances that is the cause of this peak, is written out in a JSON-file.
For each proposal in the proposals-list, a sentiment graph is plotted to visualize the sentiment for each utterance on that proposal, and how the sentiment might change over the course of number of utterances.
Proposal Data Structure in JSON Format At the conclusion of the script, the data structure of each proposal is printed in JSON format. This output provides a detailed view of the processed data, including titles, timestamps, utterances, and full text. JSON format is chosen for its readability and ease of inspection, making it convenient for further analysis or sharing of results.
Related work
Stanford NLP (Stanza)
Stanford NLP, now known as Stanza, is a robust natural language processing library developed by the Stanford NLP Group. It provides a suite of state-of-the- art tools for various language processing tasks, including tokenization, part-of- speech tagging, named entity recognition, and dependency parsing. Stanza offers pre-trained models for multiple languages, enabling users to perform complex linguistic analyses with ease. One of its key strengths lies in its deep integration with deep learning techniques, resulting in high accuracy and efficiency across a range of NLP tasks. Its focus on multilingual support makes it a versatile choice for researchers and developers working with diverse linguistic datasets. (Peng et al., 2020)
Spacy NLP
Spacy is a popular open-source natural language processing library designed for efficiency and ease of use. It excels in providing fast and accurate linguistic annotations, including tokenization, part-of-speech tagging, named entity recognition, and dependency parsing. Spacy’s streamlined API and pre-trained models make it user-friendly for both beginners and experienced developers. It is known for its efficiency, allowing for real-time application in various contexts. Spacy also supports custom model training, enabling users to adapt it to domain-specific language patterns. Overall, Spacy is a versatile tool for NLP tasks, striking a balance between performance and simplicity. (Honnibal et al., 2020)
Hugging Face Sentence Transformer (all-MiniLM-L6-v2)
Hugging Face’s Sentence Transformer library, specifically the model “all- MiniLM-L6-v2,” is a part of the broader Transformers library. It is developed by Hugging Face, a platform that hosts a vast collection of pre-trained models for natural language processing tasks. The Sentence Transformer model excels in creating embeddings for sentences or text snippets, making it valuable for tasks such as semantic similarity and information retrieval. “all-MiniLM-L6-v2” refers to the specific architecture and version of the MiniLM model used in this implementation. The Hugging Face Transformers library simplifies the integration of advanced transformer models into various NLP applications, fostering accessibility and innovation in the field. (Hugging Face, n.d)
Conclusion & Future Work
The conclusion i can draw from this project, is that the best approach to extracting usable data from the meeting notes, is to use an ensemble of different NLP libraries and techniques. Only using a single pretrained model is too inadequate for the purpose of this project.
The plots produced by the implementation in this project seem to all have a positive bias. The average sentiment from all the plots, by qualitative measure, can be estimated to be between 0.5 and 0. While there are some peaks in the graphs in both negative and positive direction, the sentiment analysis estimates most utterances to be either neutral or slightly positive.
It should be acknowledged, however, that the greatest challenge of this project has been to find a way to accurately estimate whether two, or more, discussions are talking about the same proposal. The implementation in this project is not as nuanced as it could be, and as a result the utterances measured in each proposal might not completely reflect the true evolution of sentiment of each proposal.
Runtime
The natural next steps to improve this implementation would be to improve the runtime. As of now, on an average desktop, it takes between 36 and 48 hours to create sentiment graphs for all proposals mentioned in the meeting notes, dating back to 2016. As the list of proposals in theproposals-list becomes longer, the runtime increases, due to an accumulation of unique elements.
Initially, my thought was to concatenate the fulltext of each proposal that meets the similarity threshold, to increase the accuracy of the semantic similarity calculation. However, the script eventually stopped due to lack of available RAM.
A potential avenue of investigation could be to create summaries of the full texts of each proposal and concatenate those for accurate comparison.
Unique identifier for each proposal
The greatest challenge of this project was how to determine if two sections in the meeting notes are actually discussing the same proposal. My thought was that if the semantic similarity between the two sections are above a certain threshold, they must talk about the same thing. However, this is not necessarily the case. The following scenario might be the case. A unique proposal is discussed in 2017. Later, in 2019, a different unique proposal is discussed. The later proposal,
however, is completely dependent on the earlier proposal. The discussion of the later proposal therefore contains a lot of references and discussions about the earlier proposal. By only evaluating semantic similarity, these two sections would be deemed part of the same proposal, which is not the case.
Because of this type of dilemma, an improved way of estimating similarity is necessary to accurately determine if two sections are discussion pertaining to the same proposal.
My first suggestion is to give each unique proposal discussed at the meetings, a unique identifier, e.g. “AYD245”. Then every time the same proposal is discussed, the same identifier is applied to the section in the meeting notes. This way, the estimation is no longer dependent on meeting a threshold, but rather verifying the unique identifier.
My second suggestion is to use an ensemble of different NLP techniques to create a composite score of similarity. This way, there is more nuance involved in the estimation of similarity.
References
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., Corrado, G. S., Davis, A., Dean, J., Devin, M., Ghemawat, S., Goodfellow, I., Harp, A., Irving, G., Isard, M., Jozefowicz, R., Jia, Y., Kaiser, L., Kudlur, M., Levenberg, J., Mané, D., Schuster, M., Monga, R., Moore, S., Murray, D., Olah, C., Shlens, J., Steiner, B., Sutskever, I., Talwar, K., Tucker, P., Vanhoucke, V., Vasudevan, V., Viégas, F., Vinyals, O., Warden, P., Wattenberg, M., Wicke, M., Yu, Y., & Zheng, X. (2015). TensorFlow, Large-scale machine learning on heterogeneous systems [Computer software]. https://doi.org/10.5281/zenodo.4724125
Campos, R., Mangaravite, V., Pasquali, A., Jatowt, A., Jorge, A., Nunes, C. and Jatowt, A. (2020). YAKE! Keyword Extraction from Single Documents using Multiple Local Features. In Information Sciences Journal. Elsevier, Vol 509, pp 257-289. https://doi.org/10.1016/j.ins.2019.09.013
Cer, D., Yang, Y., Kong, S.-y., Hua, N., Limtiaco, N., St. John, R., Constant, N., Guajardo-Cespedes, M., Yuan, S., Tar, C., Sung, Y.-H., Strope, B., & Kurzweil, R. (2018). Universal Sentence Encoder. arXiv preprint https://arxiv.org/pdf/1803.11175.pdf
Devopedia. 2019. “Part-of-Speech Tagging.” Version 3, September 8. Accessed 2023-11-12. https://devopedia.org/part-of-speech-tagging
Devopedia. 2020. “Named Entity Recognition.” Version 5, February 4. Accessed 2023-11-12. https://devopedia.org/named-entity-recognition
Devopedia. 2020. “Semantic Role Labelling.” Version 3, January 10. Accessed 2023-11-12. https://devopedia.org/semantic-role-labelling
Devopedia. 2020. “Text Summarization.” Version 2, February 21. Accessed 2023-11-12. https://devopedia.org/text-summarization
Devopedia. 2022. “Sentiment Analysis.” Version 52, January 26. Accessed 2023-11-12. https://devopedia.org/sentiment-analysis
Engelsen, C. (2023). sentiment-plotter [Computer software]. https://github.com/Cengelsen/sentiment-plotter
Harispe, S., Ranwez, S., Janaqi, S., & Montmain, J. (2015). Semantic Similarity from Natural Language and Ontology Analysis. Synthesis Lectures on Human Language Technologies. Springer International Publishing. https://doi.org/10.1007/978-3-031-02156-5
Honnibal, M., Montani, I., Van Landeghem, S., & Boyd, A. (2020). spaCy: Industrial-strength Natural Language Processing in Python. https://doi.org/10.5281/zenodo.1212303
Hunter, J. D. (2007). Matplotlib: A 2D graphics environment. Computing in Science & Engineering, 9(3), 90–95. https://doi.org/10.1109/MCSE.2007.55
Hugging Face. (n.d.). Sentence Transformers: MiniLM-L6-v2. Hugging Face Model Hub. Retrieved December 18, 2023, from https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
Loria, S. (2020). TextBlob: Simplified Text Processing (Version 0.16.0). Retrieved from https://textblob.readthedocs.io/_/downloads/en/dev/pdf/
Peng Qi, Yuhao Zhang, Yuhui Zhang, Jason Bolton and Christopher D. Manning. 2020. Stanza: A Python Natural Language Processing Toolkit for Many Human Languages. In Association for Computational Linguistics (ACL) System Demonstrations. 2020. https://nlp.stanford.edu/pubs/qi2020stanza.pdf
Python Software Foundation. (2023). “re” - Regular expression operations. Python 3.11. Available at: https://docs.python.org/3/library/re.html
Beliga, Slobodan; Ana, Meštrović; Martinčić-Ipšić, Sanda. (2015). “An Overview of Graph-Based Keyword Extraction Methods and Approaches”. Journal of Information and Organizational Sciences. 39 (1): 1–20. https://hrcak.srce.hr/file/207669
Appendix A. Sentiment graphs for proposals
Here are some further example graphs produced by our implementation.